Ch02-AmDB 之编码
December 2, 2022
AmDB 之编码
1. 基本类型编码 #
编码相关函数位置,amdb/sql/codec/codec.h。
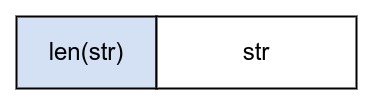
1.1 string #
编码时字符串前面追加字符长度,解码时先取出字符长度然后从后面截取出需要的字符串。
1.2 uint32/int32/uint64/int64 #
采用小端模式编码,即数字的低位存储在内存地址的低位。
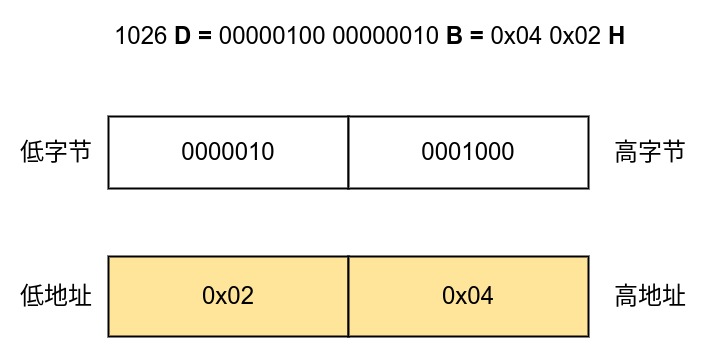
注意
这里有个与大部分习惯相悖的地方。
- 对于内存,大家习惯性的将低地址画在左边,高地址画在右边。
- 对于数字,大家习惯性的将高字节写在左边,将低字节写在右边。
纸面表达的时候,大家会习惯性的从左往右画,导致内存和数字在最终呈现形式上并不一致。
2. 复杂类型编码 #
2.1 Row (table) #
对于表里面的每行数据,都会采用下述的方式进行编码。将该行的主键编码到 key 中,将该行其他列的数据编码到 value 中。

2.2 Row (index) #
对于表里面的每行中的每列数据会按照下述方式进行编码,将该行的类型、数值、主键一同编码到 key 中,value 中不存储任何数据。所以如果一张表有多个列,这里便会生成多个 <key,value>。

与 Row (table) 不同的地方是,这里的 <key, value> 最终不会被直接存储到 leveldb 中,而是多行数据一起被编码成 BptLeafNodeRefProto 然后存储到 leveldb 中。
2.3 BptNode #
B+ 树每个节点采用 Protobuf 进行编码,对于非叶子节点按照 BptNodeProto 编码,对于叶子节点按照 BptLeafNodeRefProto 编码(其 keys 存储的是若干个 Row (index))。
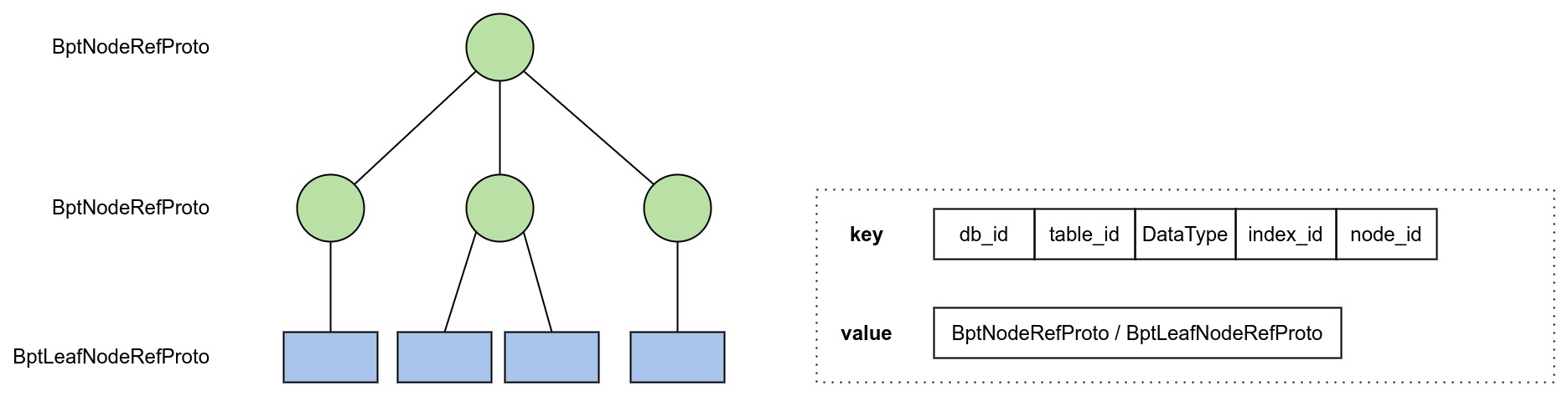
message BptNodeProto {
uint64 id = 1;
repeated BptNodeRefProto children = 2;
};
message BptLeafNodeRefProto {
uint64 id = 1;
bytes keys = 2;
bytes values = 3;
};